前言
这篇文章是最近工作的总结,受到费曼技巧的影响,还有一个简陋的PPT
背景
这篇文章的背景是游戏环境下的客服投诉系统,玩家和游戏开发者的联系不止在游戏中,很多时候,游戏开发者需要提供一个通道让玩家表达意见、怀疑与不满。很常见的情况是,
玩家想知道
- 系统公告问题(开服、合服时间)
- 装备掉落概率问题(打副本爆装备概率低)
- 系统奖励资源问题(礼包、奖励未到账)
- 游戏下载问题(下载地址)
- 关于玩家举报反馈
对于简单、重复的问题,客服常常会有一套差不多的回复。既然问题有规律/规则、有共性,那么只要识别问题的规则,面对特定的规则,自动回复特定的内容,好像就解决了。
然而,事情远远没有那么简单。我们很快开发了一套识别用户问题意图的基于规则的自动回复系统,上线运行了一段时间后,各项指标非常惨烈。分别是,
- 准确率,衡量正确识别用户意图的指标。只有85~90%
- 匹配率,衡量单位时间内匹配当前所有配置规则的指标,只有18~20%
- 召回率,衡量单个规则在同性质问题的匹配度,未统计,通过匹配率可以看出,也是相当惨烈
准确率的反面就是未解决率+错误率的总和,通过这两个反向指标,我们终于发现问题,后面会详细说说。
鸟瞰自然语言处理的历史
学习新东西,我喜欢看它的历史,从历史进程中认识发展的脉络。
我很喜欢的一个作家吴军博士,在《数学之美》一书的第二章「自然语言处理,从规则到统计」中把自然语言处理的历史讲述的非常深入人心。计算机诞生之时,科学家希望计算机能懂人类语言,于是在长达20年的时间里(1950~1970),研究人类语言的句法和语义,不断完善句法,到1960年基于规则的研究已经获得了普遍的认同。然而,局限于句法的多义性和复杂度,算法设计的复杂度也随之攀升,性能是个大问题,而且如果要让计算机认识人类语言,或许需要世界的知识和常识。
时间来到1970年代,IBM基于数学模型和统计设计的系统横空出世(准确率达到90%),让人们不禁想,也许方向错了。学派之争到了1990年代,随着参与基于规则的研究人员越来越少,参与基于统计的研究人员越来越多,自然语言处理的过渡完成了。2005年,Google基于统计的翻译系统出来后,人们终于放弃了基于规则的方法。
句法分析、语义分析
下面来看看这个简单的例子,玩家发了一条投诉意见:
你们合区啊,这区人少的,简直打不掉装备。
我们可以很容易理解,这句话的意思是需要针对「合服」类做回复。但是基于规则的自然语言处理系统能理解吗?
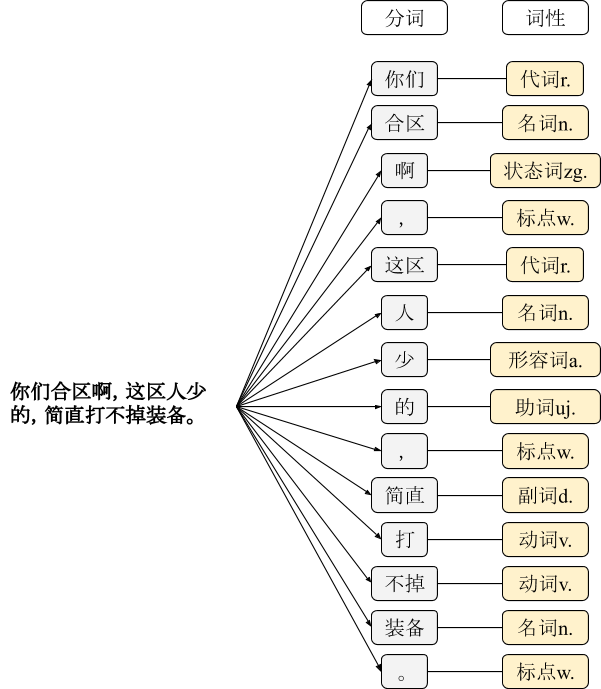
基于规则的系统会先进行分词,得到每个词的词性。简单的关键字匹配,可以得到几个有价值的关键词:合区、装备。但是我们怎么知道这是属于「合区」的类别,还是属于「概率」的类别呢?这里,机器开始不明白用户的意图了。
于是我们想,单靠一个词机器理解不了,那就再来一个。然后,我们得到了组合词规则:「合区 + 人少」、「装备 + 不掉」。我们开始思考词法和语义分析了,希望通过主谓关系来理解用户的意图,接下来你也想到了,规则的复杂度开始加大了,算法设计的复杂度也开始增加。
我们明白:人类语言的句法中含有并列、转折等多重关系,单纯的规则(关键字)无法识别用户真正的意图。
关键字
下面我们通过词云来呈现每个规则的关键词有多么复杂和庞大。


也就是说,人工设计的规则,还带来一个问题,人类语言是演进和繁杂的,而人工无法设计涵盖所有词的程序。
多义性
人工智能专家马文·明斯基举过一个例子:
The pen is in the box.(笔在盒子里。)
The box is in the pen. (盒子在围栏里。)
这是另一个无法解决的问题,中文语境博大精深,同样存在此类问题。但在今天这篇文章中,我们暂且不谈。
下面这句话摘自吴军博士《数学之美》第二章「自然语言处理,从规则到统计」
在20世纪60年代,摆在科学家面前的问题是怎样才能理解自然语言,当时普遍的认识是首先要做好两件事,即分析语句和获取语义,这实际上又是惯性思维的结果,它收到传统语言学的影响。
从规则到统计
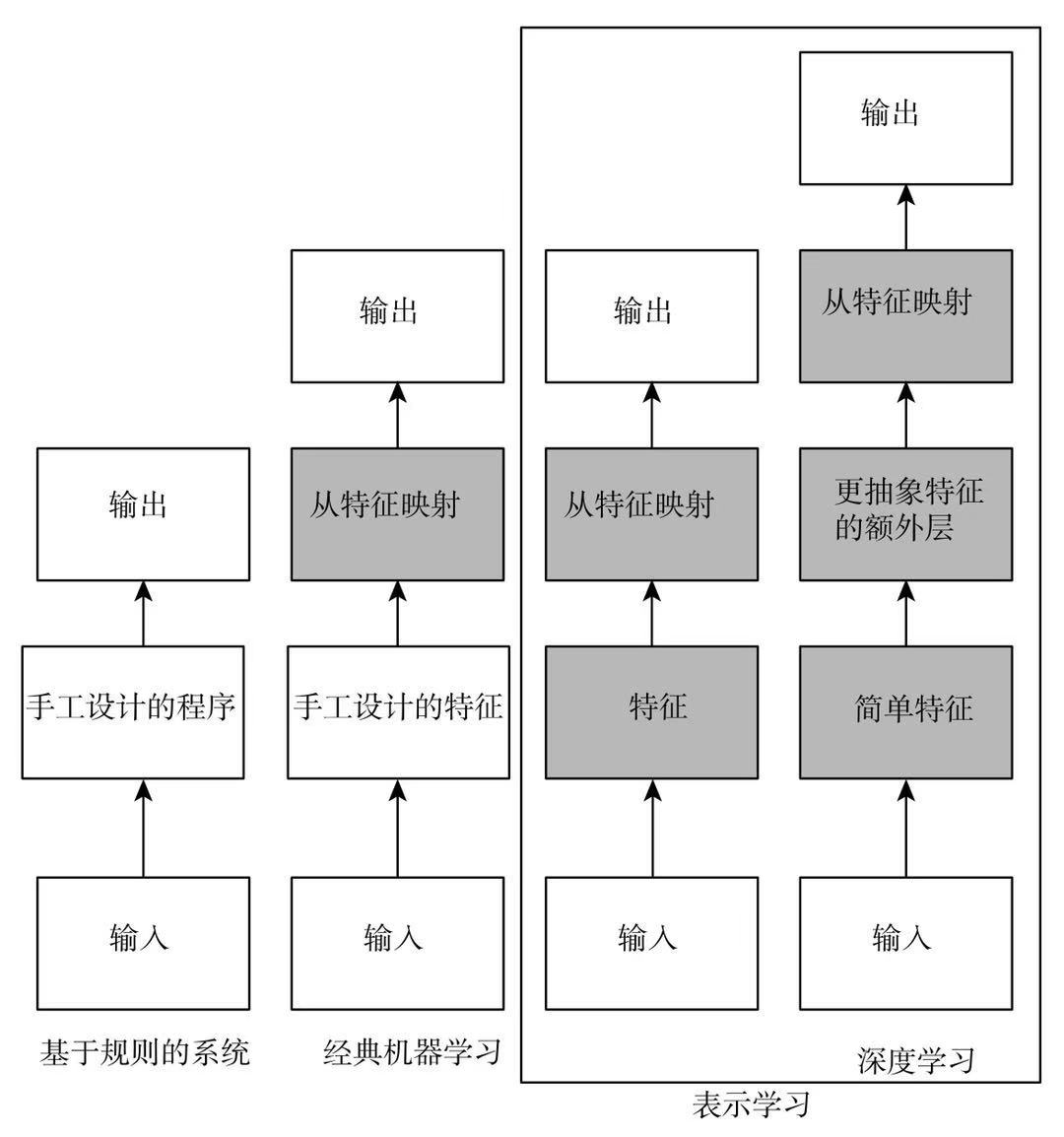
最近在读《深度学习》这本书,业界俗称「花书」。这张图很好地展示了近几十年人工智能发展的趋势。可以发现,基于规则的系统必然会成为历史。从经典机器学习到后面的表示学习,都属于基于统计的范畴。区别在于,谁来挖掘特征?经典机器学习依赖人工挖掘特征,这是大前提。意味着人去告诉/教会机器,什么是系统需要的特征,然后从特征去对应输出。表示学习就不依赖任何东西,但同样需要明确输入和输出,只是挖掘特征的过程交给模型/算法去做。
回到主题,对于文本分类领域,是否也可以使用基于统计的方法?答案是肯定的。
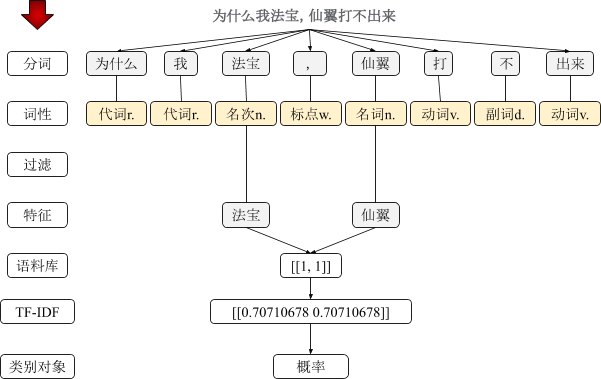
本文使用经典机器学习的方式,将文本分词,但是不使用词性。而是先过滤停用词和单词(单个文字的词)。这里,我们得到了文本的特征。到这里,你也许问,这不是和关键字一样了吗?是的,如果仅仅处理一条文本,和基于规则的方式并无二致。基于统计的精髓在于 —— 统计,这意味着庞大的样本集。
然后,我们进行特征映射,构造词袋。从词袋中,获取真正的语料,这些语料已经成为数字形式了。也就是说,从最初的文本到现在的语料,我们对文本进行了形式化处理。有了这些语料,就可以使用分类模型了。举个简单的例子,下面使用sklearn的NavieBayes模型中的GaussianNB
1 | from sklearn.naive_bayes import GaussianNB |
图中,我还用了TF-IDF,这是一种获取文本权重值的方法,可以显著提高文本分类的效果。
结合基于规则和基于统计的新方案
- 第一阶段:结合人工校对和机器分类,生成可用训练的历史投诉记录作为样本
- 第二阶段:基于充足样本数以及高准确率的机器分类,结合原方案(关键字分类)制定新策略
- 第三阶段:完成全部历史记录训练样本,并开始校对匹配记录中的机器判定结果,完成机器分类正反馈闭环
第一阶段:样本集
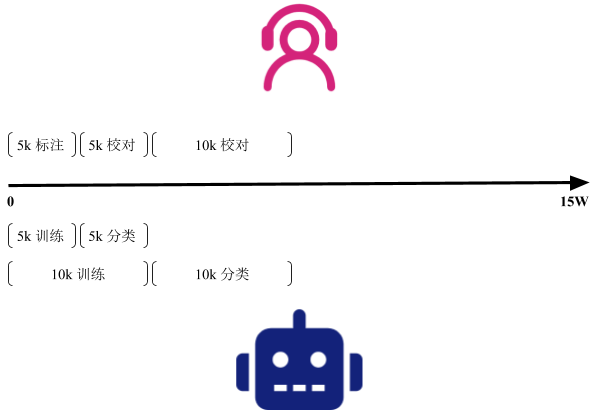
这里有15W无分类的历史记录,第一阶段也是最耗费人力、时间成本的阶段,需要非常仔细的把每一条数据对应类别,只有这样,才能称之为样本。没有做人工处理的数据,不能用于训练,在经典机器学习中,这一步尤其重要,后面我会说到为什么。总的来说就是有多少人工,就有多少智能。
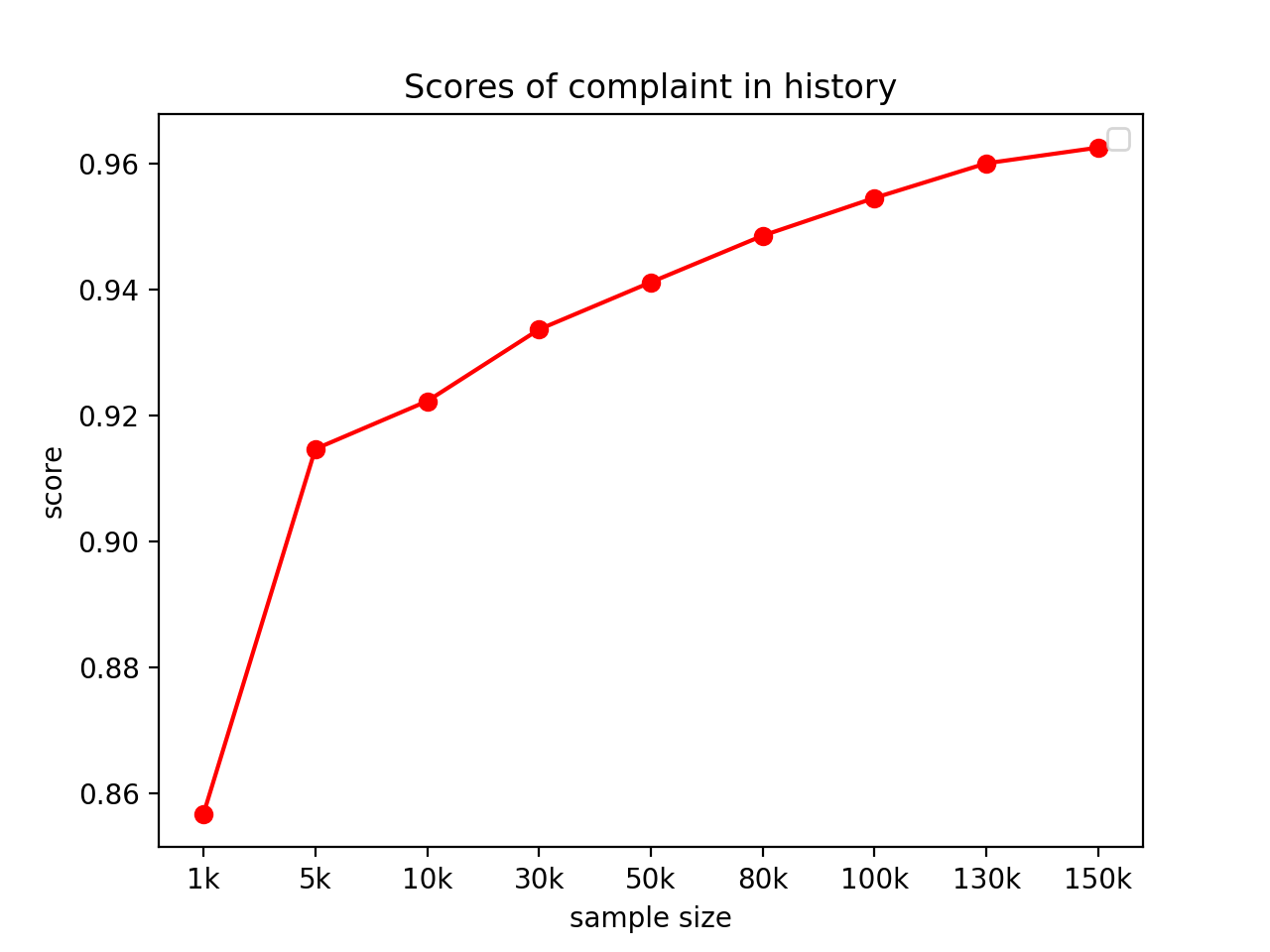
这一步是值得的,但是能不能缩短人工分类的时间?答案是肯定的。如上图所示,我们先人工分出5k样本,有朋友看到这里,也许会问,为什么是5k?而不是更大的数。这是经过验证的,5k刚好是能让大家接受的人工分类的样本数,对于我们的模型来说,5k的准确率已经相当不错了(超过90%)。为什么这么早就要聊准确率了?
接下来,我们使用这5k数据做训练,然后,给下一个5k做预测(对新的未人工分类的数据做泛化),并保存这个结果。是的,你也想到了。这5k被模型分类了一遍,虽然不是完全正确的,但是也有相当一部分是被正确归类了,相当于多了好几个人帮我们做这件事(分类速度很快,但有点粗心的人)。然后我们只需要做二次校对,把归类错误的找出来放到正确的类别即可。
不断的做增量的循环:先使用机器分类一遍,然后人工做校对。你会发现,随着数据量越来越大,正确率会非常高,后面基本就不用人工分类了,只需要扫一眼,没啥问题就过了。
让人振奋的是,这种加速机器学习的方法,原来已经被发表过了,被称为主动学习,链接:加速机器学习:从主动学习到BERT和流体标注。
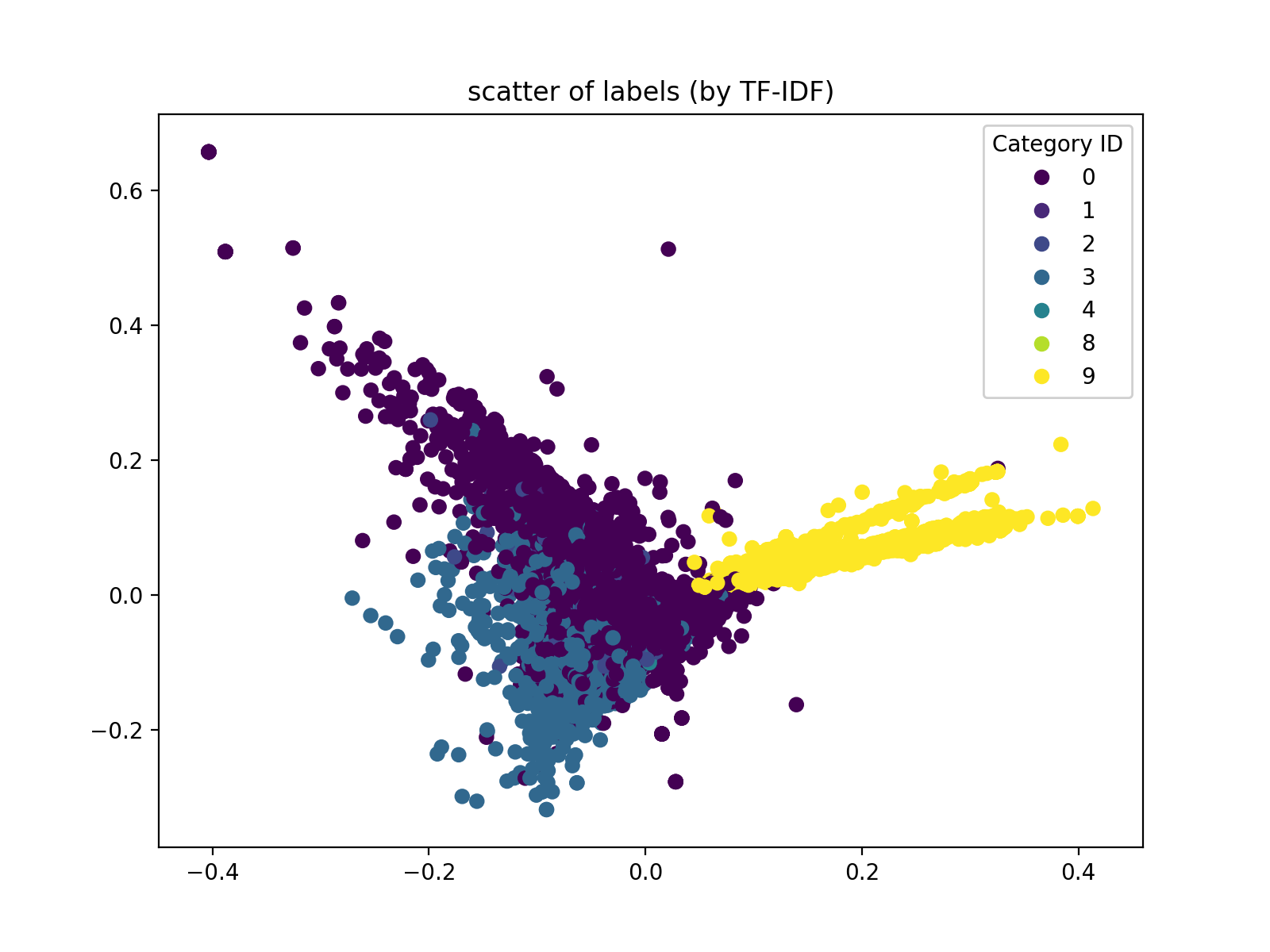
人工分完类后,我们可以得到下面的特征分布散点图(使用PCA降维TF-IDF的结果)。这个图的分布情况在一定程度上,决定了我们的模型与核函数选择
第二阶段:新策略
- 结合关键字+机器分类做判断
- 未训练或样本数较少时,使用关键字分类
- 样本集大、高准确率时,使用机器分类
| 关键字分类 | 机器分类 | |
|---|---|---|
| 匹配率 | 18% | 30% |
| 准确率 | 91% | 97% |
很快,我们就进入了第二阶段。可以发现,相比基于规则的文本分类,我们的新模型表现的更好。
第三阶段:正反馈闭环
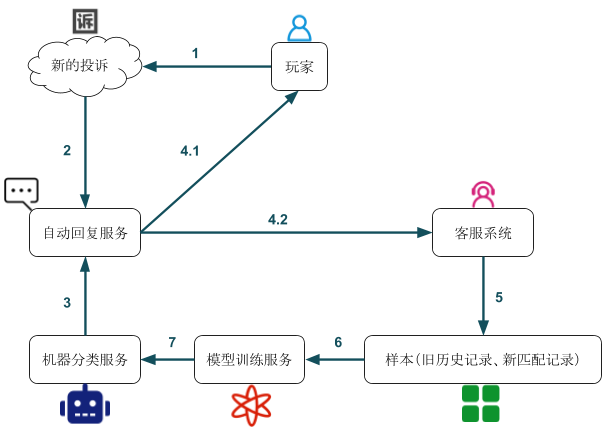
很快,我们进入了第三阶段。在第三阶段之前,模型训练的操作也是需要人员去跟进的。其实,整个系统可以产生一个正反馈闭环,模型训练可以使用定时脚本来触发。但是,为了保证模型训练的样本是正确的,还需要加入一个校对的环节。
每一次产生新的投诉,都会带来一条新的匹配记录,这条新记录是不能作为样本来训练的,需要人工进行校对,校对后的结果才能进行训练。于是,我们可以制定一个模型训练时刻,在这个时刻前,需要保证新记录是经过人工校对后的结果。
机器学习
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
我们做了一个准确率折线图,记录样本数从最初的1k到最后15W样本集的评估。可以发现,从13W样本集开始,准确率开始放缓,而不是继续往上攀升。